

Metrics for syslog-ng based log management infrastructures
Observability and the Telemetry Pipeline
Metrics have long been used to provide visibility into application environments to reduce downtime, and most observability vendors are able to aggregate and show metrics and health status for complex environments. However, in most traditional log management settings (and many new cloud-based ones), these solutions fail to provide visibility and observability for the telemetry pipeline itself, so you don’t have much insight into the operation of the data delivery mechanism. This means that your security and infrastructure teams cannot easily answer questions like these:
- Are all devices sending logs?
- Does the logging configuration of devices match the policy in effect?
- Is all data encrypted in transit?
- Am I losing messages somewhere?
- Are there bottlenecks that cause excessive delays in log collection?
- Are there any network issues that affect the log collection and delivery?
- How much data is collected from devices and device classes?
- How much data is sent to my SIEM by source/geography/team or BU?
These and similar questions are especially important if you are operating in a regulated environment and have to meet compliance requirements related to logging, such as SOC2, PCI DSS (section 10), HIPAA (NIST 800-66r2, 164.312(b)), or OMB M-21-31.
Syslog-ng has been the foundation for the logging infrastructure of many large enterprises during the last 20 years, because of its reliability, high performance, and flexibility to handle complex use cases.
We show you how you can add fleet management and observability to your existing syslog-ng infrastructure and upgrade it to a future-proof telemetry pipeline. The outlined solution supports syslog-ng Open Source Edition, the commercial syslog-ng Premium Edition, and Splunk Connect for Syslog (SC4S).
We introduce a novel method of managing telemetry pipelines that:
- Reduces the costs and resource requirements of log collection and processing
- Reduces infrastructure costs by replacing other, less effective agents and relays
- Decreases the mean time to resolution (MTTR) for issues involving your telemetry pipeline by identifying problematic cases and issuing alerts.
- Increases the reliability and robustness of your telemetry pipeline.
Though in this blog we explore the use of metrics in traditional enterprise logging environments, Axoflow supports full cloud-native environments as well, making it possible to combine your on-premises and cloud-native logging solutions (like OpenTelemetry) into a single telemetry pipeline.
Metrics and Enterprise Logging
Metrics is one of the three main pillars of observability, and can be used very effectively to gauge the proper operation of traditional, syslog-based logging pipelines. It provides visibility into key operational characteristics of these environments and ensures that data is properly collected, secured, and delivered to downstream applications.
Independent of the log payloads themselves, metrics can answer questions about the proper operation of your telemetry pipeline, for example:
- Where did this log event come from?
- Region, Data center, Rack
- IP address, Hostname
- K8s cluster, Namespace/pod/container
- What percentage of my logs are from:
- Different device types in my enterprise?
- Different geographies?
- Different applications?
- Pipeline operations, providing visibility and measurement of:
- Routes (sources and destinations)
- Incoming/Outgoing rates (EPS)
- Network/CPU/Disk utilization
- Message delays
- Drops (especially UDP)
- Incorrectly formatted data (missing timestamp, encoding issues, etc.)
To collect metrics and metadata that help you answer these questions, you need the agent as close to the original source of the log data as possible – ideally on the same host or next-hop relay if that’s not possible. Also, you must be able to:
- Add context and environment-related labels and metrics to the logs.
- Add custom metrics related to configuration elements of your log collector agent.
Metrics in syslog-ng
Syslog-ng, from its inception, has had certain metrics capability. You could get statistics on the operation of syslog-ng, which were often helpful in debugging configuration errors and basic operations. However, these were mostly built-in global statistics; you couldn’t get metrics based on the processed data.
Using recent syslog-ng versions, you can create labeled metrics and counters based on the fields of the messages that are processed in a syslog-ng log path. The custom metrics that result provide metadata that is much more pertinent to your specific use cases, and go significantly beyond the standard “state of health” metrics of the server itself.
The Axoflow Management Plane can then visualize the collected metrics to help answer pipeline-related questions at a glance.
Syslog-ng and Axoflow
The Axoflow Platform is an end-to-end observability pipeline solution that simplifies the operation of your telemetry infrastructure.
Once you onboard an existing syslog-ng deployment to Axoflow, it starts periodically sending metrics back to the Axoflow Management Plane for visualization and alerting. Note that Axoflow collects detailed, real-time metrics about the data-flows – giving you observability over the health of the security data pipeline and its components. Your security data remains in your self-managed cloud or in your on-prem instance where your sources and destinations are running, only metrics are forwarded to the Axoflow Console.
The syslog-ng deployment can be an official syslog-ng Open Source Edition (4.2+), syslog-ng Premium Edition (7.0.34+), or even a containerized syslog-ng distribution like AxoSyslog and Splunk Connect for Syslog (SC4S).
The following diagram shows how the Axoflow Management Plane (which is a Software as a Service solution) communicates with a syslog-ng deployment.
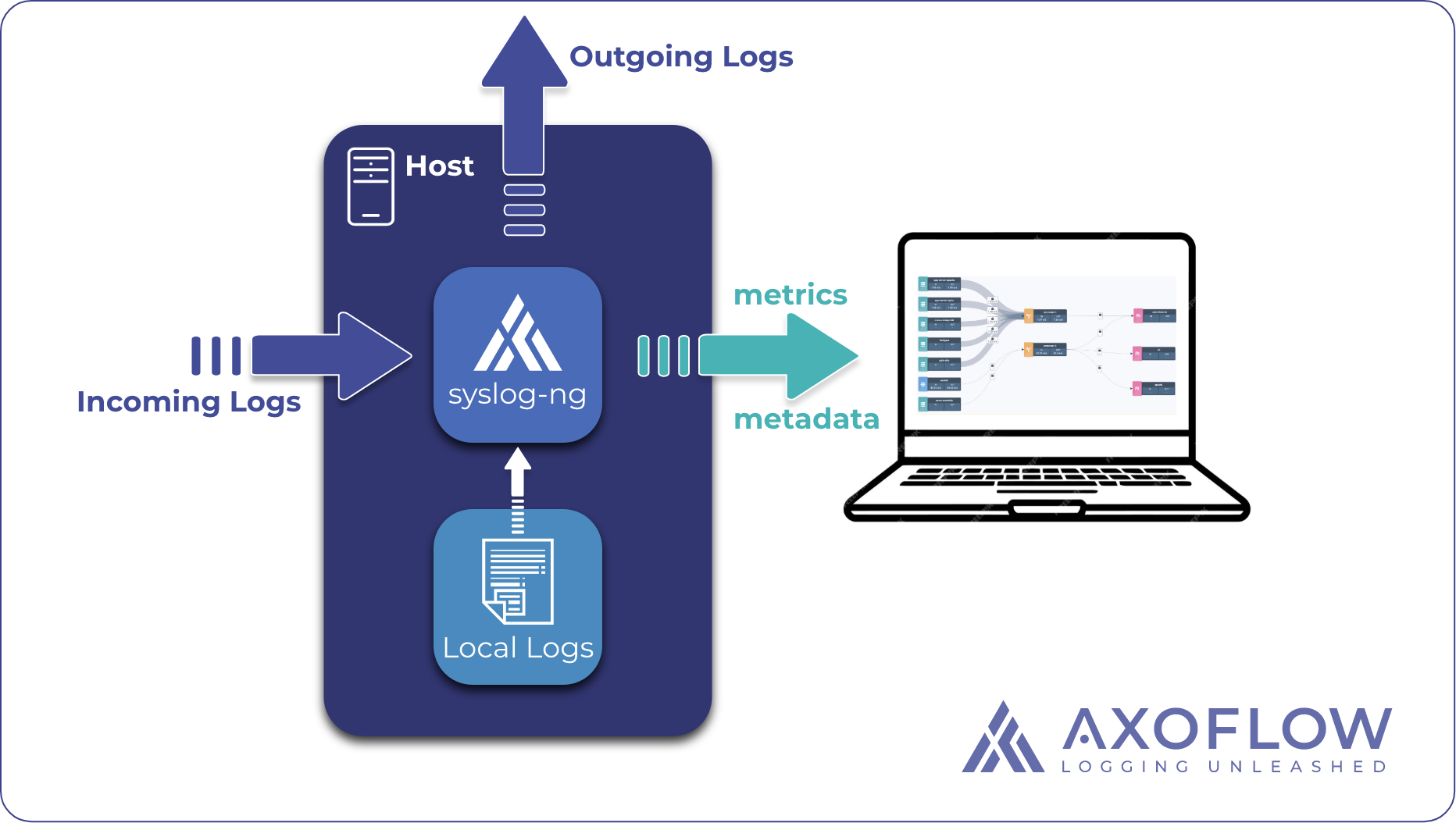
You can read more about how a syslog-ng instance is instrumented in our whitepaper.
Pipeline-related incidents often manifest themselves in:
- excessive volumes (a run-away sender generating a huge amount of logs),
- increased delays (due to network or CPU bottlenecks), or
- data format errors.
Metrics are an effective means to find the root cause for these incidents, thereby they are important tools to reduce the MTTR. The Axoflow Management Console can visualize and alert on the collected metrics about your telemetry pipeline, in both on-premises and Kubernetes environments. For a deep-dive into metrics, see How to collect AxoSyslog metrics into Prometheus.

Topology of the telemetry pipeline
In a typical enterprise environment, the telemetry pipeline can become a complex beast. Different classes of devices, using different collection strategies, agents, and protocols are part and parcel of large installations. By analyzing these metrics, Axoflow can reconstruct the delivery paths and visualize the global topology of your telemetry pipeline from edge to edge, including source hosts/applications, forwarders, syslog relays, and destinations.
Sources include appliances and other devices that cannot be onboarded to Axoflow directly but send their logs to such hosts. The metrics also allow you to show information about the traffic, such as events per second or bytes per second, as well as the type of protocol used and whether the channel is encrypted or not.

Syslog-ng host metrics
Sometimes, a telemetry-related bottleneck is caused by the limited resources of the hosts running the infrastructure. To remediate these issues, information about the host is crucial. For this reason, Axoflow collects host metrics so you can get up-to-date status and health information. In addition to generic metrics like CPU and memory usage, you also get syslog-ng-specific information, like the status of the disk buffer or the version of syslog-ng.

Alerting and Reporting
Metrics and visualization is a great tool to diagnose an incident once you are already aware that the incident is happening. Based on the collected metrics, you can create alerts for system health, data volume, data dropouts, data bursts, and critically, transport costs.

The Axoflow Management Plane
Axoflow’s ability to pull metrics from various collection agents means that you have a unified view of all your telemetry data pipelines. That way you know system health, destinations, and sources at a glance, and can rely on the Axoflow Management Plane to alert you to problems that otherwise would go unnoticed. When problems arise, the Management Plane provides full visibility, alerting, and reporting on the relationships between the data flows, the network, and the servers, meaning that you can quickly isolate issues and take action to correct the problems.
This all helps site reliability, but the benefits of a well-run log collection layer are actually felt beyond that, as the entire firm's operational and security posture is improved. Firms can optimize their collection layer by identifying redundant processes, reducing the amount of data loss, and optimizing the data flows for the intended destinations. The entire attack surface can be reduced with this kind of insight, and the entire organization will benefit.
Using the Axoflow Management Plane with your syslog-ng based logging infrastructure:
- Reduces the costs and resource requirements of log collection and processing
- Reduces infrastructure costs by replacing other, less effective agents and relays
- Increases mean time to resolve (MTTR) for issues involving your telemetry pipeline
- Increases the reliability and robustness of your telemetry pipeline
- Increases the effectiveness of SIEM and log management operations, including far more efficient and effective detection engineering
Why Axoflow?
Our founders include the original creators of syslog-ng and the Logging Operator for Kubernetes, and other main contributors to these projects, with vast knowledge and hands-on experience in observability, log management, and how to apply these technologies in the enterprise security context.
Axoflow is the biggest contributor to both syslog-ng Open Source Edition and the Logging Operator (now a CNCF sandbox project). We also maintain an up-to-date version of the syslog-ng documentation.
Where are we going?
Axoflow’s flexible architecture future-proofs the telemetry pipeline and keeps it agnostic. This means that the Management Plane will continue to work for you as new destinations and technologies are built. Automation of pipelines and the use of AI to automatically classify logs and send them to the proper destinations are coming. The Management Plane will enable teams to validate service uptimes, loss, and other variables related to the data-feeding critical backend systems like the SIEM. Teams will spend less time building difficult log collection environments and spend more time on business-related tasks.
For more details on how we can help your logging and security teams, read the AxoRouter, the security data curation pipeline engine blog post.



Follow Our Progress!
We are excited to be realizing our vision above with a full Axoflow product suite.
Sign Me UpFighting data Loss?

Book a free 30-min consultation with syslog-ng creator Balázs Scheidler