

Getting firewall logs into Splunk with Axoflow
Security teams rely on firewalls as a critical source of telemetry—but the logs these devices generate are notoriously messy. Whether it’s non-standard syslog formatting, unstructured payloads, or the overhead of building and maintaining custom parsers, getting clean, actionable data into your SIEM is a recurring pain point. Traditional solutions like parsing in the SIEM itself (e.g., using Splunk Technical Add-ons) fall short—not just in functionality, but in cost efficiency. If you're paying to ingest malformed or redundant data, you're overspending. The better approach? Fix the data before it hits your SIEM. In this post, we’ll walk through how the AxoRouter component of the Axoflow Platform transforms raw log messages into structured, routed, and optimized events—reducing noise, cutting costs, and improving downstream analytics.
As we’ve discussed in the Parsing firewall logs with FilterX blog, even the most widely used commercial products (like well-known firewalls) have issues with their logging, including:
- Malformed messages that don’t comply with syslog standards
- Message payload is unstructured, meaning that it’s a huge string (for example, a CSV) that needs to be parsed to have meaningful fields in Splunk
- Creating and maintaining parsers requires significant know-how
The usual way to fix such data problems and apply parsing is to use data processing in the SIEM (just think of Splunk Technical Add-ons). However, this is ineffective, because in the SIEM you can't solve:
- Log size reduction. The data is already in the SIEM and you've paid for it at ingestion time.
- Routing. A SIEM is most often a final destination for the data, and you can't really forward the parts that you'd rather need somewhere else, for example, to monitoring or analytics systems, low-cost storage, or nowhere (because it's not security-relevant, like debug logs).
- Cost reduction. An expensive aspect of the data quality problem is its cost: ingesting data into your SIEM has become way too expensive. At over 25% average YoY increase in the collected data, organizations are overspending because of volume-based licensing.
We believe, like the analysts of Gartner and Forrester, that the solution is in the pipeline. Let’s go through a series of examples to show how sending data that has been preprocessed to different levels changes what you get in your SIEM. In the examples we use Splunk, but the same principles apply to other SIEMs as well.
Raw message forwarding
First, let’s send a message from a Palo Alto firewall to AxoRouter (the data processing and routing engine of the Axoflow Platform). In this case, AxoRouter directly forwards it to the HTTP Event Collector (HEC) endpoint of Splunk, without any parsing, classification, or fixup. As you can see in the screenshot, the result in Splunk is underwhelming:
- The data is dumped into the default index
- There’s no sourcetype attribution
- There are no fields extracted from the message, so it’s just a long string
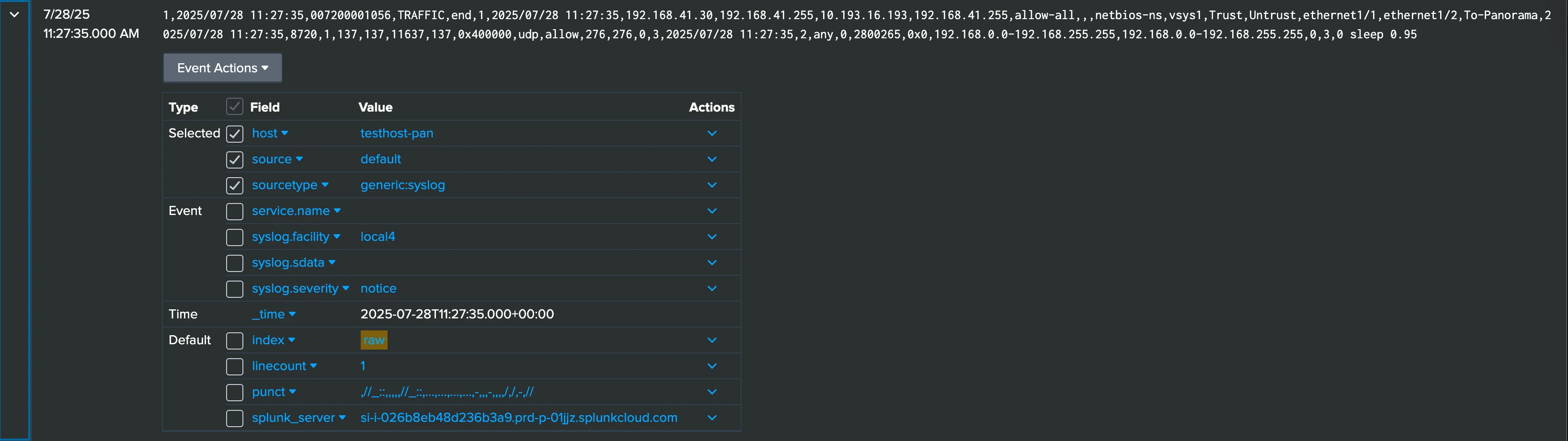
Not really comfortable to work with. As a minimum, you need a way to set the sourcetype for your logs.
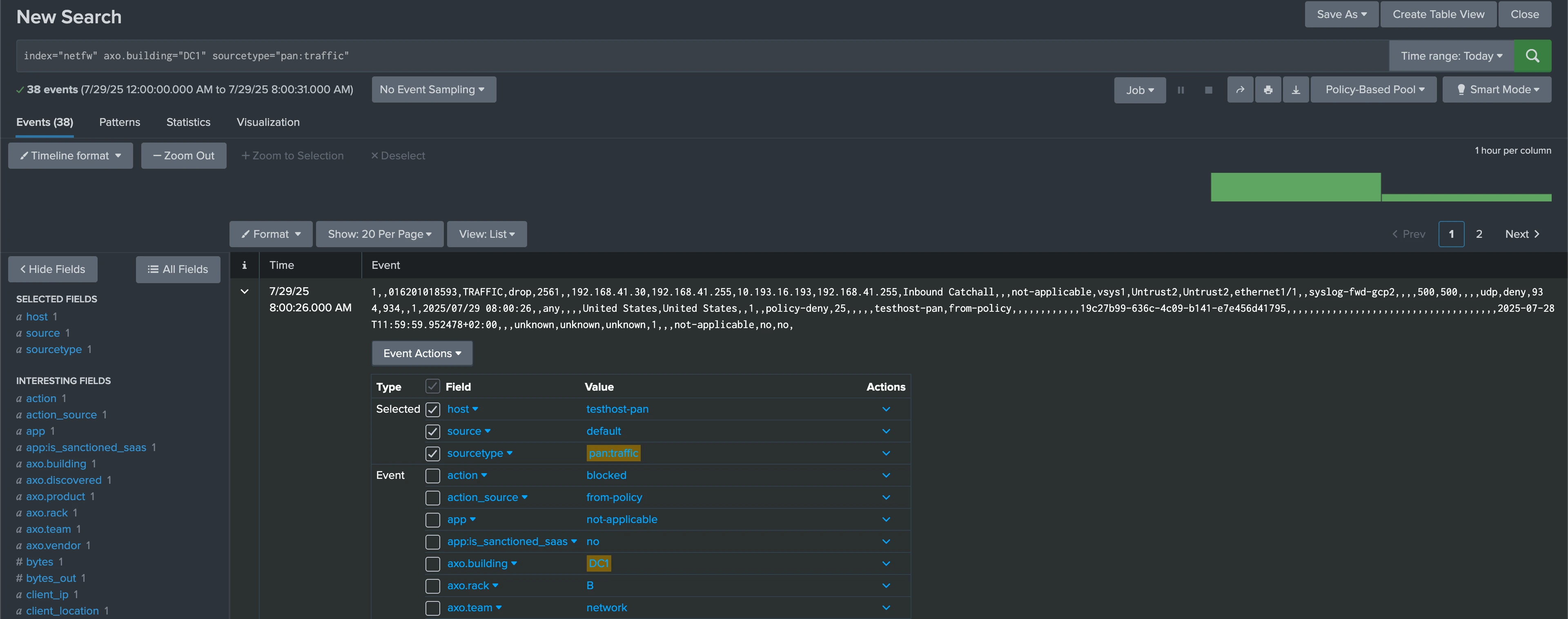
Sending classified data
Next, enable classification in AxoRouter. This allows AxoRouter to:
- automatically recognize the message,
- determine which product and vendor sent it,
- set the proper sourcetype based on the message content (for example,
pan:traffic), and - send the message to the proper index (for example,
netfw)
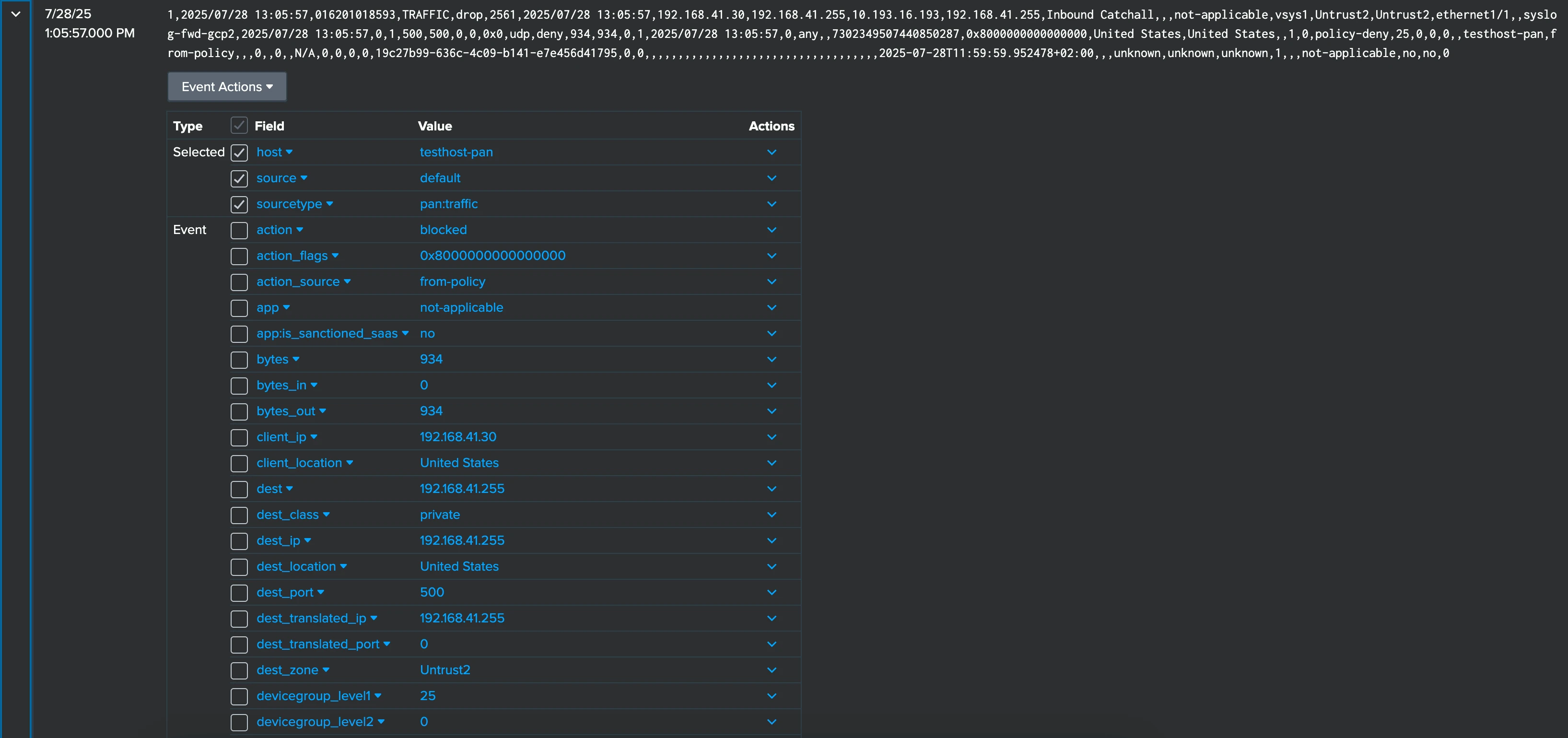
Classification in AxoRouter analyzes the message to identify it, but doesn’t modify the message itself, so the message body itself is still a string. That way, the data remains in the same format as the related Splunk technology add-ons (TAs) and apps expect it, so if you already have them installed, you have access to the fields of the message content.
Sending structured data
Let’s make the message more useful: enable parsing in AxoRouter. This way in addition to classifying the message, AxoRouter parses the content of the message and replaces it with structured data.
Sending this data to Splunk (or another SIEM) means that the fields of the message will be accessible for Splunk, so you can use it in queries, even if you don’t have specific add-ons in Splunk. Parsing also paves the way to manipulate the data, to enrich it and discard what’s not really needed.
Data reduction
Parsing the content of the messages makes it possible to transform and modify it, for example, to:
- remove unneeded fields,
- reduce the amount of data ingested, or
- normalize messages and field names.
In Axoflow, you can even check what happens with the message in the different processing steps. Here’s a partial screenshot of the automatic reduction step for the message used in the earlier examples:
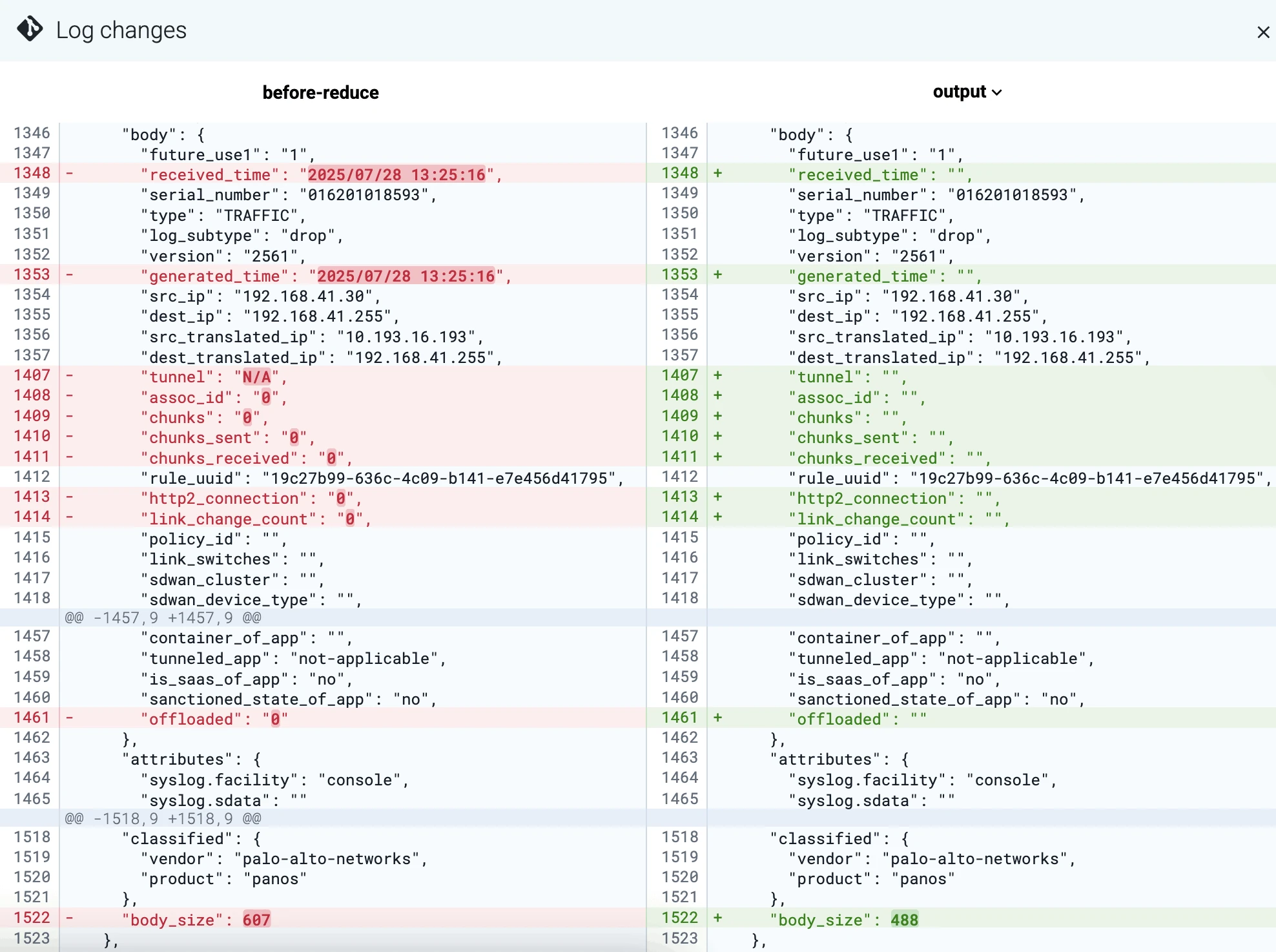
In the text format that’s sent to Splunk, the difference is:
- Original message, 428 bytes:
<165>Jul 28 14:25:04 us-east-1-dc1-b-edge-fw 1,2025/07/28 14:25:04,007200001056,TRAFFIC,end,1,2025/07/28 14:25:04,192.168.41.30,192.168.41.255,10.193.16.193,192.168.41.255,allow-all,,,netbios-ns,vsys1,Trust,Untrust,ethernet1/1,ethernet1/2,To-Panorama,2025/07/28 14:25:04,8720,1,137,137,11637,137,0x400000,udp,allow,276,276,0,3,2025/07/28 14:25:04,2,any,0,2516399,0x0,192.168.0.0-192.168.255.255,192.168.0.0-192.168.255.255,0,3,0- Reduced message, 249 bytes:
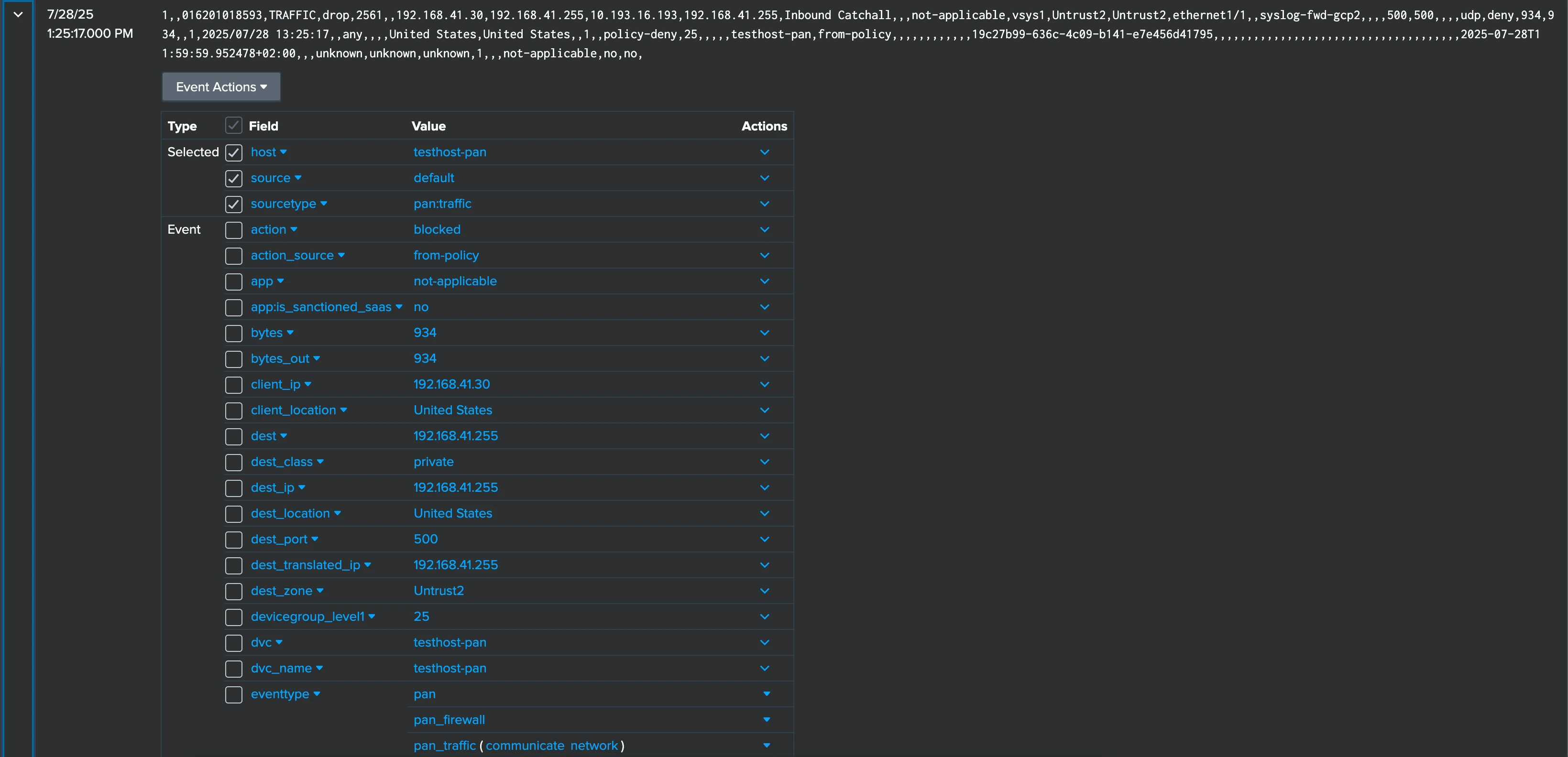
1,,007200001056,TRAFFIC,end,1,,192.168.41.30,192.168.41.255,10.193.16.193,192.168.41.255,allow-all,,,netbios-ns,vsys1,Trust,Untrust,ethernet1/1,ethernet1/2,To-Panorama,,8720,,137,137,11637,137,,udp,allow,276,276,,3,2025/07/28 14:25:04,2,any,,,,,,,3,The size of the sample message was reduced by ~42%, as it’s also apparent on this screenshot:

And all the relevant fields extracted from the message content are still there:
Enriching data
Enriching data and adding relevant context helps your teams to find the information they need, write better alerts and queries, and to faster pinpoint what’s happening in case of an issue. With Axoflow, you can add both static and dynamic labels to your data, for example, static information about your hosts like their location, and dynamic labels based on their content. For example, adding location-related labels like building identifier or rack number to your on-prem hosts (or similar data in cloud environments) makes it really easy to narrow your searches to data that’s relevant to your investigation.
Conclusion
Manage your security data pipeline with Axoflow Platform, which includes optimized message parsing for over a hundred ubiquitous products. That way you can:
- Solve your data parsing issues automatically
- Deliver high-quality, optimized data to your SIEM
- Gain insight into the status of your data pipeline to avoid losing data
- Remove noise and redundant data to cut your SIEM and storage costs
You can try all of that in action using a free Axoflow Sandbox and your own Splunk deployment (or a free Splunk Cloud account).

Follow Our Progress!
We are excited to be realizing our vision above with a full Axoflow product suite.
Sign Me UpFighting data Loss?

Book a free 30-min consultation with syslog-ng creator Balázs Scheidler